

VisDom enables high-quality reconstruction from as few as 4 input views.
Without VisDom, general-purpose methods fail catastrophically at this sparsity; our constraint recovers photorealistic results.
1TU Munich · 2MCML · * equal contribution
VisDom enables high-quality reconstruction from as few as 4 input views.
Without VisDom, general-purpose methods fail catastrophically at this sparsity; our constraint recovers photorealistic results.
Sparse novel view synthesis (NVS) remains challenging due to the ambiguity of recovering 3D geometry from few input views. While NeRF- and Gaussian Splatting (GS)-based methods perform well with dense supervision, they often overfit in sparse settings, producing floating artifacts and inconsistent geometry. Silhouette consistency is commonly used as a regularizer, but it remains insufficient, as silhouette-consistent regions can extend beyond the true object geometry.
We introduce VisDom, a learning-free geometric constraint that augments classical carving-based visual hull reconstruction by enforcing a minimum multi-view visibility requirement. Specifically, we define a visible domain as the subset of 3D space observed by at least K views and use it as an additional filtering criterion on top of standard silhouette-based reconstruction. This provides a stronger spatial prior in sparse-view settings.
We integrate VisDom into both implicit (NeRF) and explicit (GS) pipelines by restricting volumetric sampling and guiding Gaussian placement during optimization. Experiments on three challenging datasets show consistent improvements in sparse-view NVS, enabling high-quality object-centric reconstruction from as few as four input images. Our method is domain-agnostic, requires only silhouettes, and introduces no learned parameters, making it a simple complement to existing approaches. Applying VisDom on top of GaussianObject further improves performance on Omni3D and MipNeRF360, while matching or surpassing it at 22× lower training cost.
Augments the classical visual hull by retaining only 3D regions observed by at least K cameras — removing ambiguous space that silhouettes alone cannot resolve.
Integrates into any NeRF (via ray-sampling bounds) or 3DGS pipeline (via Gaussian placement and interpolated-view supervision) with a single modification.
Zero learned parameters, no domain-specific training data, and no generative priors — relies solely on silhouettes extracted by off-the-shelf segmentation models.
NeRF and 3DGS allocate density or place Gaussians without global geometric regularization, leading to floaters and structural inconsistencies in sparse settings. Adding a silhouette loss only carves out space excluded by silhouettes — but with few views the resulting visual hull is enormous, providing weak guidance and sometimes degrading performance (ZipNeRF+mask drops from 12.44 to 11.95 dB at 4 views on MipNeRF360).

We define the visible domain as the subset of 3D space jointly observed by at least K cameras. This is applied on top of standard voxel carving: a voxel is retained only if (i) its occupancy votes exceed 95% of its visibility votes (standard hull) and (ii) it is visible from at least K cameras (our constraint). This removes weakly constrained voxels that are a primary source of spurious density in sparse reconstruction.

The VisDom visual hull is used to restrict each ray's sampling range [tn, tf] by intersecting it with the visual hull mesh. Rays only sample within the tightly constrained region, preventing density accumulation in ambiguous space. Combined with a silhouette loss (λ=0.1), this turns previously unusable methods into competitive ones.
For 3DGS, we (1) initialize Gaussians from the VisDom visual hull mesh instead of COLMAP, and (2) penalize Gaussians that appear opaque outside the visual hull when rendered from interpolated camera views. This removes ghost-like floaters and confines the reconstruction to the visible domain.
We ablate K ∈ {1, 2, 3, 4} on MipNeRF360. K=1 degrades to near-vanilla (unconstrained hull). K=2 eliminates most ambiguous space. K=3 achieves the best mean for ZipNeRF (25.99 dB) and is chosen as the default — it balances hull tightness against the risk of over-carving surface regions visible from only a few cameras at the hardest 4-view setting.
| Views | ZipNeRF + VD (PSNR ↑) | 3DGS-GO + VD (PSNR ↑) | ||||||
|---|---|---|---|---|---|---|---|---|
| K=1 | K=2 | K=3 | K=4 | K=1 | K=2 | K=3 | K=4 | |
| 4 views | 13.55 | 22.71 | 24.10 | 23.79 | 13.23 | 23.98 | 24.06 | 24.00 |
| 6 views | 16.21 | 21.47 | 25.80 | 22.04 | 18.23 | 27.17 | 26.72 | 26.56 |
| 9 views | 18.66 | 28.06 | 28.06 | 28.71 | 24.16 | 29.06 | 28.45 | 28.54 |
| Mean | 16.14 | 24.08 | 25.99 | 24.84 | 18.54 | 26.74 | 26.41 | 26.36 |
Ablation of K on MipNeRF360. K=3 provides the best mean across all view counts for ZipNeRF; K=2 peaks for 3DGS-GO but leaves residual floaters. We use K=3 as default.
We evaluate vanilla, +mask (silhouette loss only), and +VisDom on two NeRF methods and one 3DGS pipeline. This isolates VisDom's effect from any sparse-specific inductive biases.
| Dataset | Views | Instant-NGP | ZipNeRF | 3DGS-GO | |||||
|---|---|---|---|---|---|---|---|---|---|
| Vanilla | +mask | +VD | Vanilla | +mask | +VD | Vanilla* | +VD | ||
| MipNeRF360 | 4 | 13.67 | 13.73 | 22.15 | 12.44 | 11.95 | 24.10 | 23.61 | 24.06 |
| 6 | 14.73 | 17.36 | 24.14 | 11.89 | 12.78 | 25.80 | 26.30 | 26.72 | |
| 9 | 16.04 | 20.74 | 25.43 | 14.85 | 19.87 | 28.06 | 27.93 | 28.45 | |
| Omni3D | 4 | 18.88 | 18.16 | 27.44 | 15.04 | 15.02 | 29.49 | 29.80 | 30.32 |
| 6 | 19.95 | 22.01 | 29.67 | 16.61 | 20.00 | 32.28 | 33.09 | 33.37 | |
| 9 | 20.86 | 22.31 | 31.06 | 23.16 | 25.30 | 35.21 | 35.49 | 35.69 | |
| ActorsHQ | 5 | 12.01 | 13.87 | 23.53 | 10.85 | 10.33 | 24.55 | 25.12 | 25.69 |
| 8 | 13.86 | 14.96 | 23.35 | 11.43 | 10.76 | 26.72 | 27.44 | 27.99 | |
| 12 | 20.98 | 24.86 | 25.67 | 11.32 | 28.38 | 28.61 | 28.80 | 29.13 | |
PSNR ↑ on three datasets. Green = best per-method variant. +VD consistently wins over Vanilla and +mask. *Vanilla = GaussianObject initialization stage only.
VisDom is applied to CoR-GS and GaussianObject (GO) and benchmarked against state-of-the-art sparse NVS methods. CoR-GS+VD leads on MipNeRF360; 3DGS+VD leads on ActorsHQ. GO+VD achieves the best Omni3D mean. Importantly, 3DGS+VD trains in just 2 minutes per scene — 22× faster than GO — while remaining competitive.
| Dataset | Cams | VaxNeRF | ZeroRF | SplatFields | FSGS | CoR-GS | GO | INGP+VD | ZipNeRF+VD | 3DGS+VD | CoR-GS+VD | GO+VD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train time → | 1h | 14m | 10m | 45m | 20m | 40m | 2m ⚡ | 10m | 45m | |||
| MipNeRF360 | 4 | 18.14 | 14.17 | 22.24 | 23.38 | 24.04 | 24.02 | 22.15 | 24.10 | 24.06 | 24.64 | 24.16 |
| 6 | 20.39 | 24.14 | 24.57 | 26.17 | 25.81 | 26.23 | 24.14 | 25.80 | 26.72 | 27.35 | 26.50 | |
| 9 | 21.53 | 27.78 | 26.58 | 28.16 | 28.58 | 27.94 | 25.43 | 28.06 | 28.45 | 29.32 | 28.14 | |
| Mean | 20.02 | 22.03 | 24.46 | 25.91 | 26.14 | 26.06 | 23.91 | 25.99 | 26.41 | 27.10 | 26.27 | |
| Omni3D | 4 | 18.35 | 27.78 | 28.49 | 27.31 | 28.97 | 30.37 | 27.44 | 29.49 | 30.32 | 29.82 | 30.71 |
| 6 | 19.60 | 31.94 | 32.05 | 29.74 | 32.51 | 33.26 | 29.67 | 32.28 | 33.37 | 32.87 | 33.29 | |
| 9 | 20.91 | 32.93 | 34.66 | 33.46 | 34.94 | 35.56 | 31.06 | 35.21 | 35.69 | 35.56 | 35.59 | |
| Mean | 19.62 | 30.88 | 31.73 | 30.17 | 32.14 | 33.06 | 29.39 | 32.33 | 33.12 | 32.75 | 33.20 | |
| ActorsHQ | 5 | 13.14 | 25.13 | 22.16 | 24.44 | 24.94 | 24.91 | 23.53 | 24.55 | 25.69 | 25.27 | 24.85 |
| 8 | 14.51 | 26.47 | 24.67 | 26.48 | 26.93 | 26.98 | 23.35 | 26.72 | 27.99 | 27.06 | 26.87 | |
| 12 | 15.27 | 27.59 | 26.90 | 27.96 | 28.21 | 28.17 | 25.67 | 28.61 | 29.13 | 28.22 | 28.10 | |
| Mean | 14.31 | 26.40 | 24.58 | 26.29 | 26.69 | 26.69 | 24.18 | 26.63 | 27.60 | 26.85 | 26.61 | |
PSNR ↑ comparison. Green = best, Blue = second best per row. Lavender-shaded columns = our VisDom variants. VaxNeRF and ZeroRF both train in 2h (shown as a grouped label).
As the minimum visibility threshold K increases, the visible domain tightens, carving out more ambiguous space. The traditional visual hull (K=1) retains large, poorly-constrained regions; VisDom at K=3 yields a compact, reliable shape.







Top row: the visible domain (region jointly observed by at least K cameras) shrinks as K increases. Bottom row: the resulting visual hull becomes progressively tighter and more accurate. The traditional hull (K=1) is overly permissive; VisDom at K=3 carves out all ambiguous space.
Adding a silhouette mask loss alone is insufficient — and sometimes harmful — at low camera counts. VisDom restricts ray sampling to the jointly-visible region, enabling faithful reconstruction from very few views.
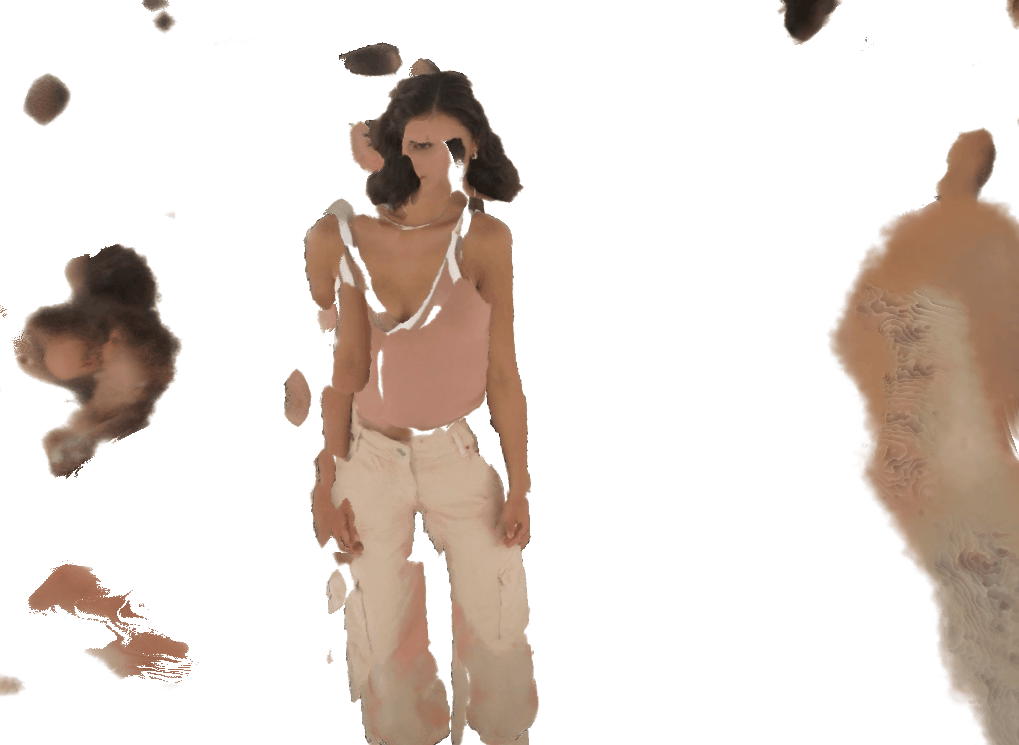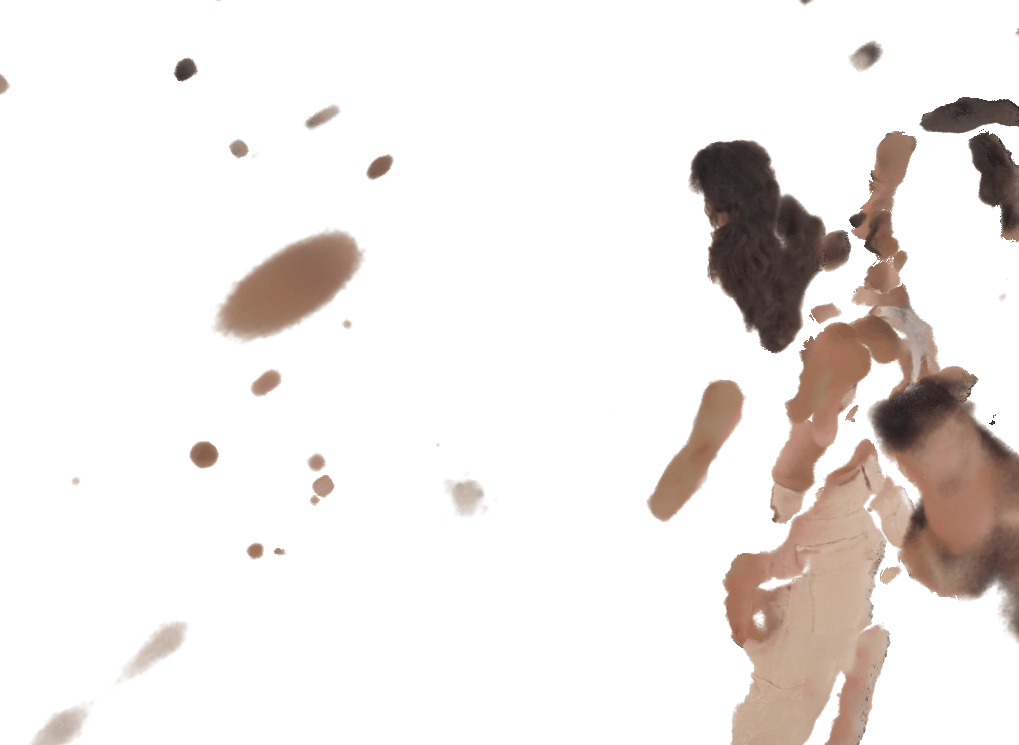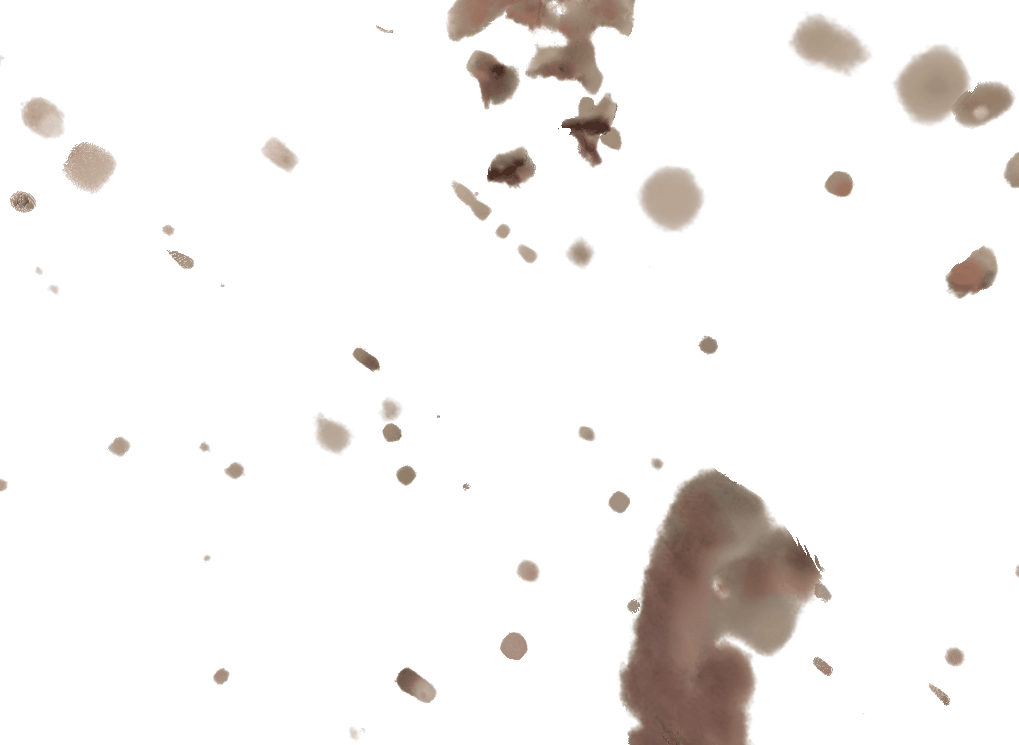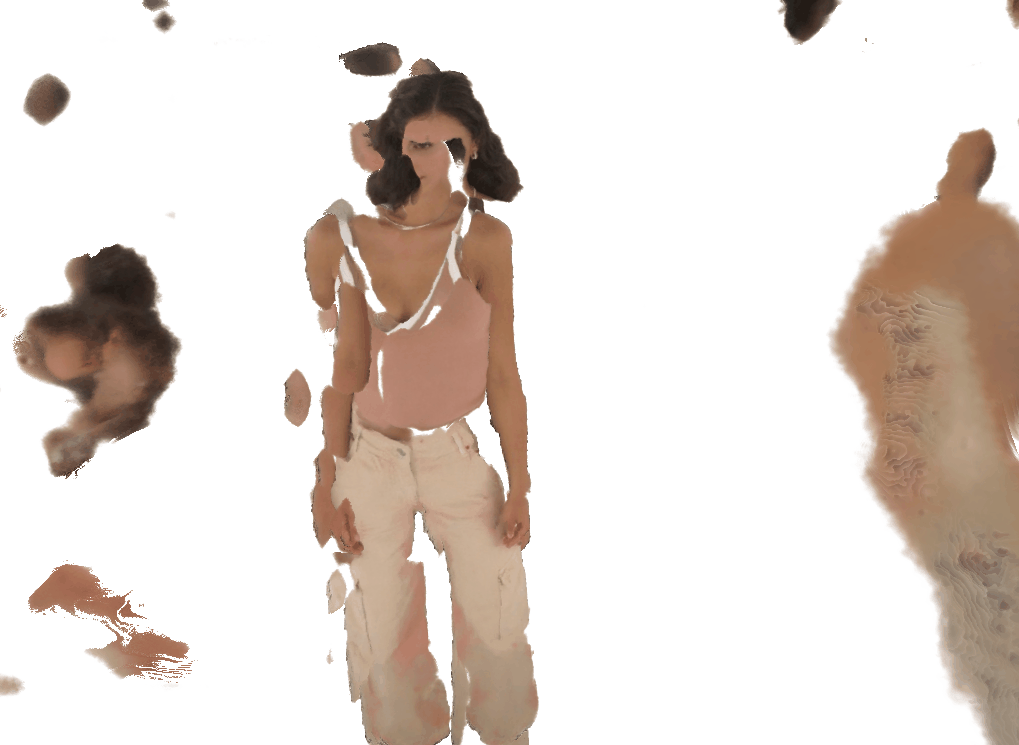




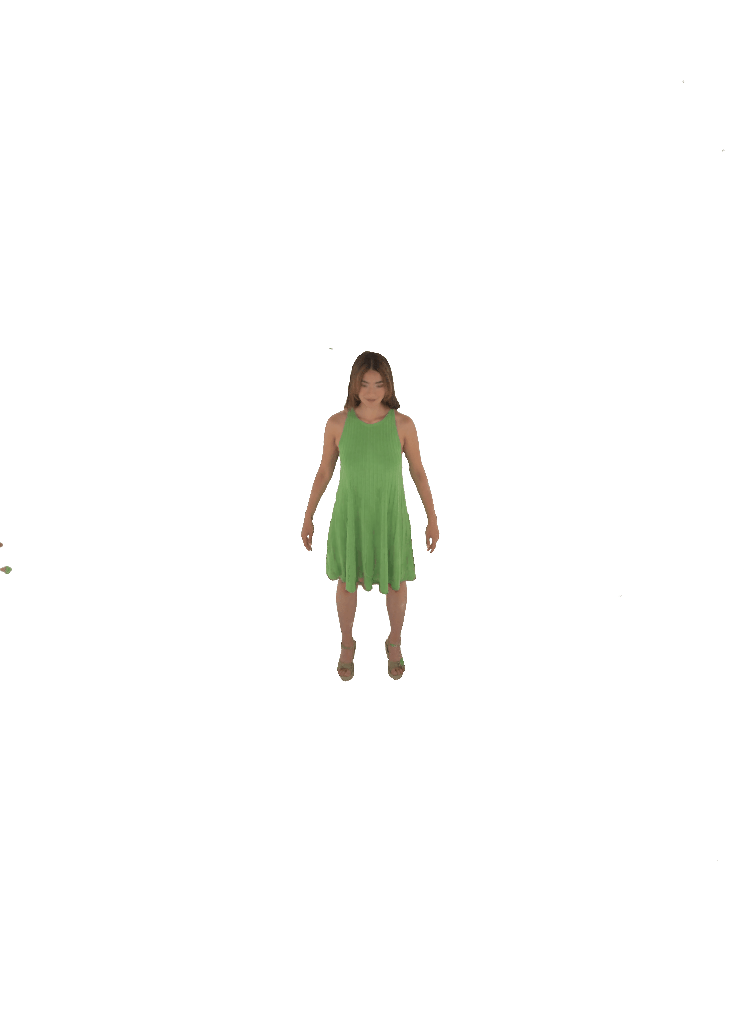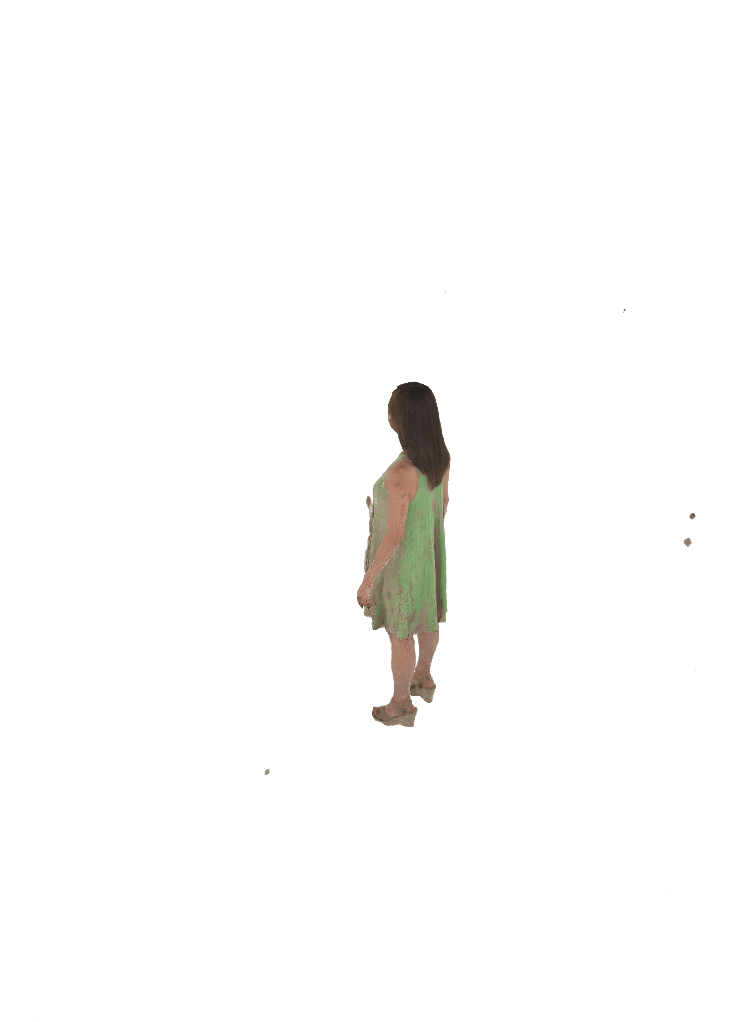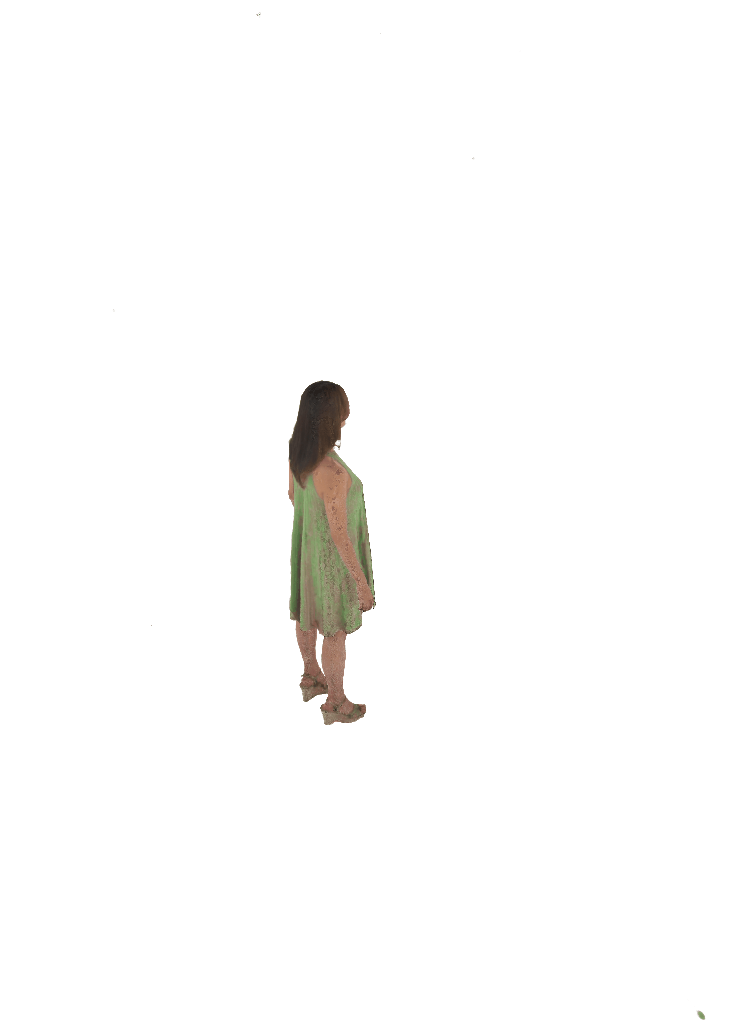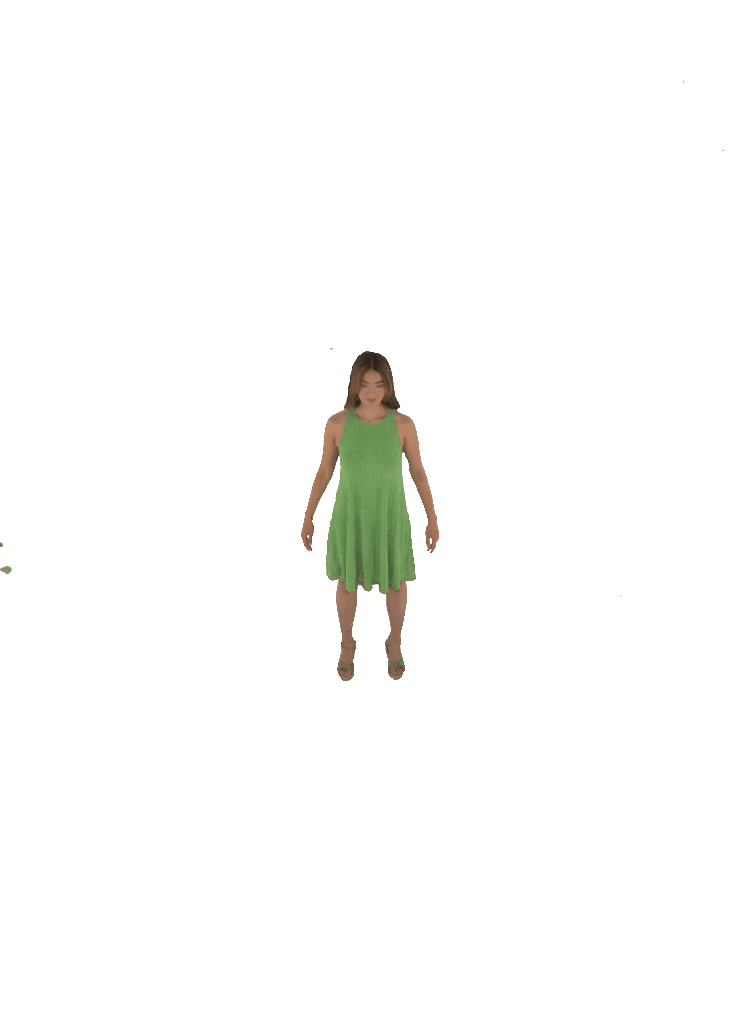




Each pair shows a 360° render from ZipNeRF trained with silhouette mask only (left) vs. with VisDom (right). Floaters and geometry collapse are eliminated by VisDom across all camera counts.
VisDom guides Gaussian placement during optimization, suppressing floaters that 3DGS-GO places in ambiguous free space. The improvement is most pronounced at 4 cameras and remains consistent as coverage increases.
360° renders from 3DGS-GO (left) vs. 3DGS-GO + VisDom (right) at 4, 6, and 9 input cameras. VisDom removes Gaussian floaters by restricting placement to the jointly-visible domain.
We presented VisDom, a learning-free geometric constraint that tightens the classical visual hull by restricting reconstruction to the region jointly visible in at least K views. A key finding is that silhouette supervision alone is insufficient at extreme sparsity — and can actively harm convergence — because the resulting visual hull is too large. VisDom resolves this by enforcing K-view co-visibility, removing ambiguous volume that silhouettes cannot resolve. The constraint adds only a 2-second preprocessing step and zero learned parameters, and integrates with any NeRF or 3DGS pipeline via a single modification.
Across five reconstruction frameworks and three real-world datasets, VisDom consistently improves quality — enabling general-purpose methods that completely fail without it (up to ~90% PSNR gain at 4 views), advancing sparse reconstruction models, and delivering competitive results without any additional learned parameters.